Also interchangeably referred to as incremental learning #IL and lifelong learning.
Motivation/Challenges:
Motivation:
We will never stop finding newer classes. This means models deployed should keep learning new classes continuously.
Challenges:
Catastrophic forgetting #CF found to be the biggest challenge in literature - where the model tends to forget about the past knowledge to focus more on the newest tasks, leading to a performance degradation on previous tasks.
Repeated data collection on the same routes - how efficient is it to keep encountering new classes.
MLO Group @ Goethe University Frankfurt (DKTK Consortium) under Prof. Florian Buettner:
This research group seems to be quite active in this field.
Following the classification proposed by Mai et al. (2022), class-IL approaches can be grouped into the following categories: a) Regularization techniques that adjust the model parameter updates by incorporating penalty terms in the loss function (Aljundi et al., 2018; Lee et al., 2017), modifying parameter gradients during optimization (Chaudhry et al., 2018b; He & Jaeger, 2018), or employing knowledge distillation (Wu et al., 2019; Rannen et al., 2017); b) Memory-based techniques in which a fixed-size subset of past samples is stored for replay (Aljundi et al., 2019a; Chaudhry et al., 2019) or for regularization purposes (Nguyen et al., 2018; Tao et al., 2020) ; c) Generative-based techniques which involve training generative models to produce pseudo-samples that replicate the information from past tasks (Lesort et al., 2019; Shin et al., 2017), and d) Parameter-isolation-based techniques that allocate distinct model parameters to each task, either by activating only the relevant parameters for each task (Fixed Architecture) (Mallya & Lazebnik, 2018; Serra et al., 2018) or by adding new parameters while keeping the existing ones unchanged (Dynamic Architecture) (Yoon et al., 2018; Aljundi et al., 2017) [¹]
Open-ended recogntion
Open-ended approaches for object detection/segmentation enable the segmentation of novel objects (previously unseen) at test time without assigning them a predefined label, but instead generating free-form descriptions.
Motivation/Challenges:
Motivation:
According to DB Systemtechnik's presentation (19.03.2026 / Slide 15), the description generated on the GUI (that is then sent to the dispatcher) needs to be sufficiently specific.
Challenges:
Is this description only available to the dispatcher (since the driver must not be distracted with the GUI)?
Emerging field, few publications available (almost none from the industry).
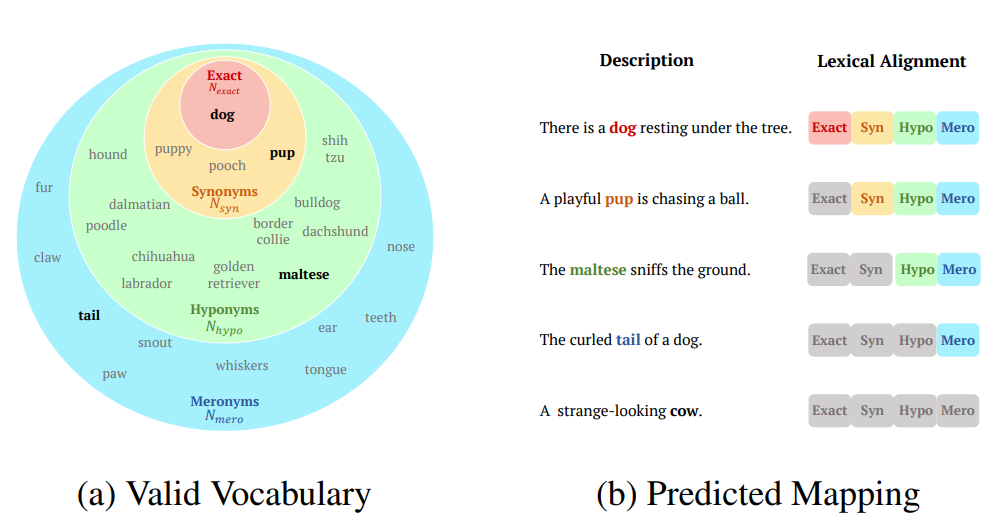
These can differ in wording, granularity, or structure while still conveying the same concept. Multiple valid descriptions (e.g. “yellow dog,” “golden retriever,” or “a dog’s tail”) can refer to the same entity, and thus rigid label-matching metrics fall short in capturing semantic correctness. This one-to-many relationship between ground-truth concepts and acceptable linguistic expressions motivates the need for evaluation methods that go beyond exact string matching. Prior studies (Guo et al., 2024; Huang et al., 2024; You et al., 2023; Yuan et al., 2024) have repurposed metrics from related vision-language tasks to assess generalization in open-ended visual recognition, where free-form text outputs are typically scored with captioning metrics (Anderson et al., 2016; Banerjee & Lavie, 2005; Lin, 2004; Papineni et al., 2002; Vedantam et al., 2015) [²]