Data
Q: Why and how do we collect scale up data collection efficiently?
Dataset pruning and selection:
Aims to identify smaller subsets of training data by removing redundant samples while preserving model performance. Two main categories: density-based and model-based.
- Extending this idea to specific tasks like object detection has been investigated before[¹]. In [1],
Data mixtures:
Aims to mix data from different domains (distributions) for model-training.
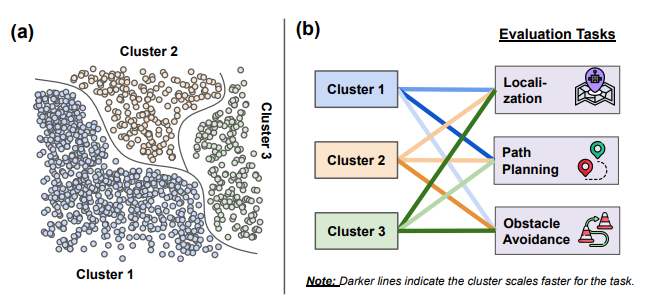
- Found in literature [²] only for #E2E approaches - Ours is not. I am not 100% sure if this idea makes sense.
[1] Kang et al. 2025 https://openreview.net/forum?id=hGipI51ljh
[2] Dimlioglu et al. (CVPR 2026) https://arxiv.org/pdf/2604.08366